Zippatron
One day I thought “what if you zip something multiple times?” It probably just gets bigger right? We’ll see. Also, what do different compression programs do? We’ll see that too.
I tested 3 files (IMG7110.jpg: a 22MB 6000x4000 image, lmms.AppImage: the 92MB AppImage for LMMS, and rand: 100MB of random bytes) with 7 crompression programs: xz, gzip, bzip2, lzip, lzma, lzop, and zstd. Each time, I compressed the original file, then repeatedly compressed the new archive 16 times in a row.
Every time I zipped a file I wrote a line to a CSV file with these columns:
file: the original file nameout: the output archive namezipper: the compressor that was usediter: which iteration of zippingtime: how long it took to zipsize: how big the output file was
Then I wrote a Python Notebook that makes some cool graphs. The exported notebook is here, and here are the graphs:
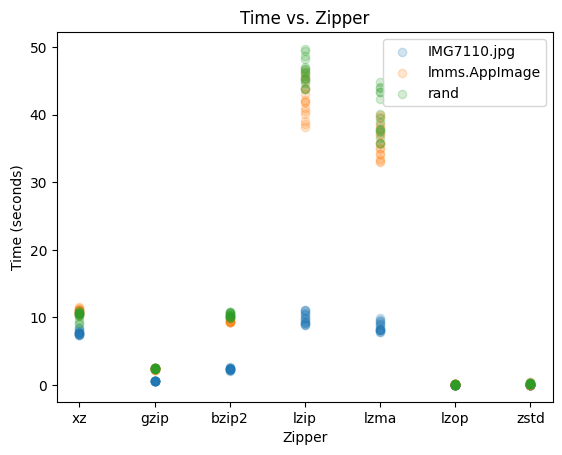
lzip and lzma are interesting because they were pretty fast on the JPEG, but a lot slower on the AppImage and random data.
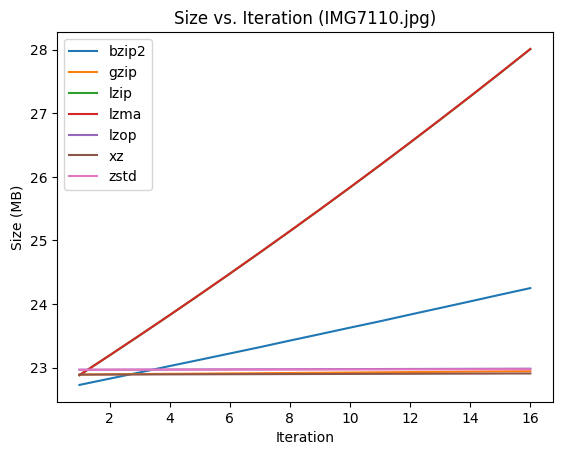
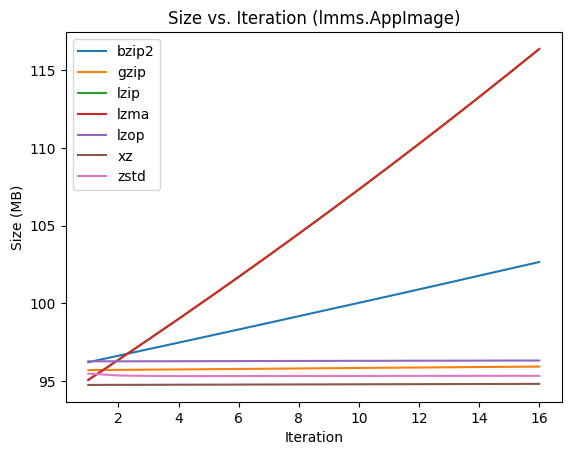
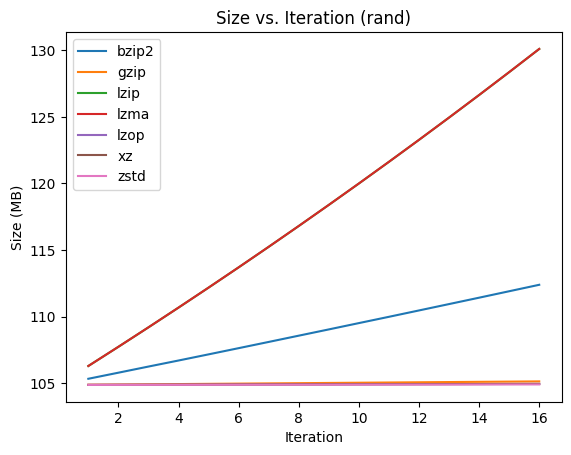 Here you can see that everything is pretty much linear, with the same amount of data being added on every compression,
Here you can see that everything is pretty much linear, with the same amount of data being added on every compression, lzma adding the most, and gzip, zstd, xz, and lzop not adding much.
After sorting the files by size, I saw that the smallest was IMG7110.jpg compressed once with bzip2 at 22,196 bytes.
Very strange thing: the first file I used to test this was a 229MB RWP file (flowers-d.rwp), which is just a bunch of the same words so it’s easy to compress. For some reason, the smallest file was from running bzip2 twice, the file size going from 229MB, to 7,736 bytes on the first zip, to 7,656 on the second zip. Why is bzip like this?
GitHub repo: CalSch/zippatron